

「AIエージェント導入失敗9割の壁」を超える企業は、何を持っているのか ——MIT Technology Reviewより
AIエージェントを業務に組み込んだ企業のうち、実運用までスケールできたのはわずか10社に1社——。2026年3月、MIT Technology Reviewが公開した特集「Building a strong data infrastructure for AI agent success」は、AI導入の競争に走るすべての経営者に、不都合な事実を突きつけた。失敗は、モデル性能の問題ではない。
McKinseyの年次調査では、2025年末時点で約3分の2の企業がAIエージェントを実験中で、88%が少なくとも一つの業務領域でAIを使っている。投資は積み上がっているのに、現場で動かない。なぜか。記事が示した答えは明快である。AIエージェントは、それを支えるデータ基盤の質を超えて賢くなることはできない、ということだ。
私はエンタープライズ企業向けにAIトランスフォーメーション(AX)を支援する立場で、日本の数多くの大企業の経営変革現場に入ってきた。痛感するのは、MIT Technology Reviewが指摘した世界共通の構造と、日本企業が直面している障壁が、ほぼ同じだということである。「AIが期待ほど効かない」と感じている経営者の大半は、モデルそのものではなく、自社のデータが「文脈を欠いた状態」で散らかっていることに突き当たっている。
データ量ではなく、ビジネス・コンテキストが価値を決める
SAP Data & AnalyticsのIrfan Khan社長は、記事の中で「真のリスクはデータ不足ではなく、グラウンディング(接地)の欠如である」と語る。AIに大量のデータを食わせれば賢くなる、という発想はもう通用しない。サプライチェーンの判断、財務計画、顧客対応——これらの意思決定はすべて文脈依存である。同じ「在庫1万個」というデータでも、その背後にある販売チャネルの動き、過去の判断履歴、顧客とのやり取りがなければ、AIが正しく動く根拠にはならない。
記事は、構造化データ=高価値、非構造化データ=低価値、という従来の二分法を退ける。AI時代に価値を決めるのはフォーマットではなく、文脈なのだ。IDEA(Institute for Data and Enterprise AI)の調査によれば、3分の2のビジネスリーダーが自社データを完全には信頼していない。記事はこの状態を「Trust Debt(信頼の負債)」と呼ぶ。Deloitteの「State of AI in the Enterprise」では、データ管理プロセスがAI対応できていると答えた企業は10社中わずか4社で、しかも前年の43%から低下している。AI展開に踏み込むほど、自社インフラの不備が見えてくる——この皮肉な構図が、世界中で進行中である。
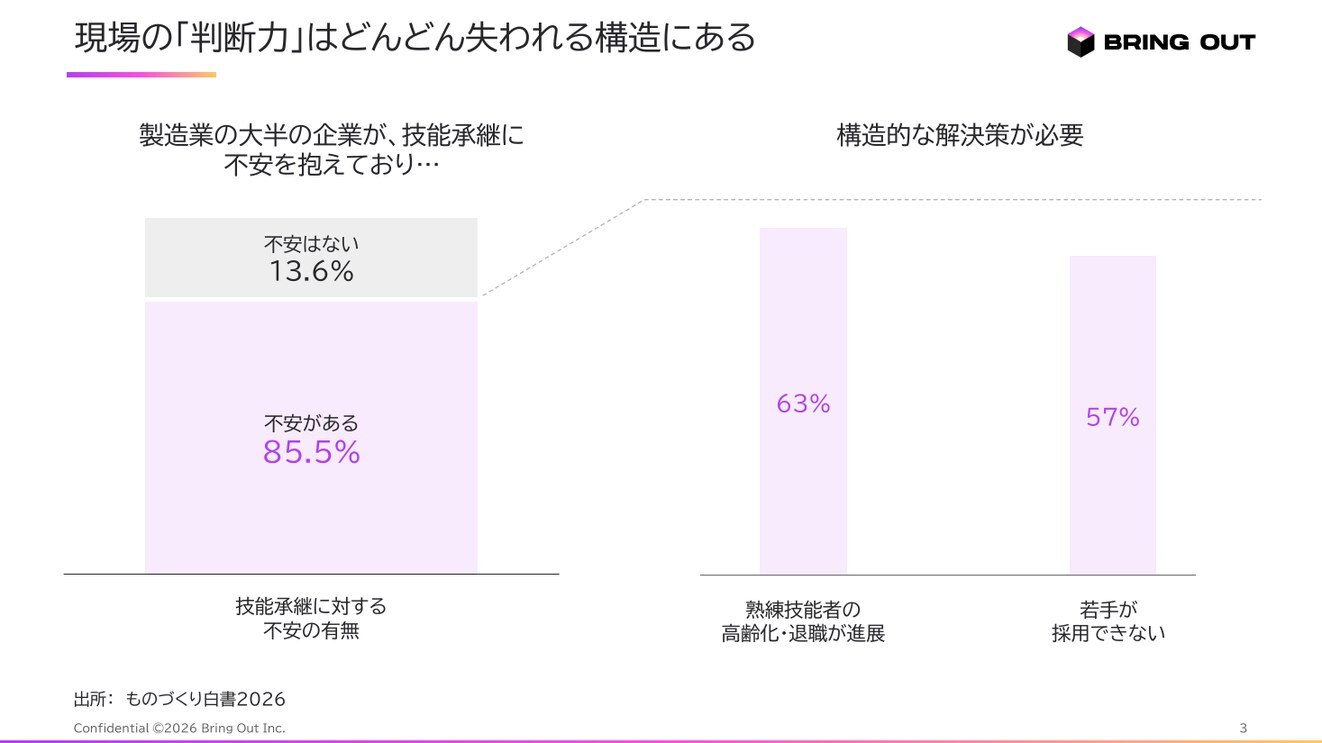
これは、日本企業にとっても遠い話ではない。ある製造業の地方拠点で、ベテラン営業が顧客の生産ラインの調子を毎週見て回り、「来月、彼らはたぶん予備部品を3割増やしてくる」と感じている。本人の経験則として極めて精度が高い。だがその情報は、月一の所長への口頭報告でしか上がらず、本社の需要計画に届く頃には数字の中に溶けて消えている。経営陣はダッシュボードを見ながら「うちはデータドリブンだ」と言う。だが、そのダッシュボードに乗っているのは加工済みの数字であって、現場の感触ではない。データはあるが、コンテキストが欠落している、というのはこういう状態だ。
SaaSを消すのではなく、その上に新しい層を重ねる
「AIエージェントがSaaSを陳腐化させる」という言説に、Khan氏は明確に反対する。価値はオンプレ→IaaS→PaaS→SaaSと積み上がってきたが、下層が消えたわけではない。エージェンティックAIはその上に乗る「新しいエンゲージメント層」である。SaaSは引き続きSystem of Recordであり、その上に「セマンティック層」がビジネス・コンテキストのSingle Source of Truthとして必要になる。エージェントはこの層を介してSaaSとビジネスロジックにアクセスする——というのが彼の示す重層モデルだ。
エージェントが業務基幹システム一つひとつに直接つながる未来は来ない。各システムは固有のスキーマと運用ルールを持ち、それを横断的に翻訳できるセマンティック層が不可欠だからである。問題は、その層を誰が、どんな素材から、どう作るかである。
二次情報依存ではなく、一次情報を経営に直結させる
2026年4月、KADOKAWAから拙著『生成AIで最強の組織が生まれる——トップと現場をつなぐ一次情報経営』を刊行した。本書の中核命題はこうだ。「AI時代の経営とは、現場の一次情報を要約に変える前に、構造化して経営判断に直結させる仕組みを作ることである」。MIT Technology Reviewが言うセマンティック層を、日本企業の組織文化に当てはめると、まさにこの一次情報の流通網になる。
なぜ日本企業に「一次情報」というキーワードが効くのか。日本企業の競争優位は、もともと現場の暗黙知に強く依存してきた。製造業の品質、サービス業の対応力、商社の取引先理解——これらは数字化されたKPIではなく、現場の人間が肌で感じている「シグナル」の集積で動いてきた。にもかかわらず、日本の経営は二次情報(要約レポート、加工済み数字)への依存度が高い。会議資料は美しく、図表は整っているが、生の手触りを持った情報が経営層まで上がるルートが細い。結果として、現場が知っていることのうち、経営の意思決定に反映されるのはごく一部にとどまる。

この構造的なボトルネックは、AI以前から存在していた。だが、生成AI時代に決定的な意味を持つようになった。AIエージェントは、要約された二次情報ではなく、鮮度の高い一次情報と接続されたときに最も価値を発揮するからである。AIの真価は、二次情報の生成スピードを上げることではない。二次情報を介さずに、現場の一次情報そのものを経営の判断に届けることにある。

全自動を急ぐのではなく、最も鮮度の高い一次情報から始める
Khan氏は記事の終盤で、重要業務の完全自動化を急ぐべきではないと釘を刺す。「初期の成果は、重要度の低いプロセスや、古いダッシュボードではなく新鮮でステートフルなデータで動くエージェントから生まれる」と。
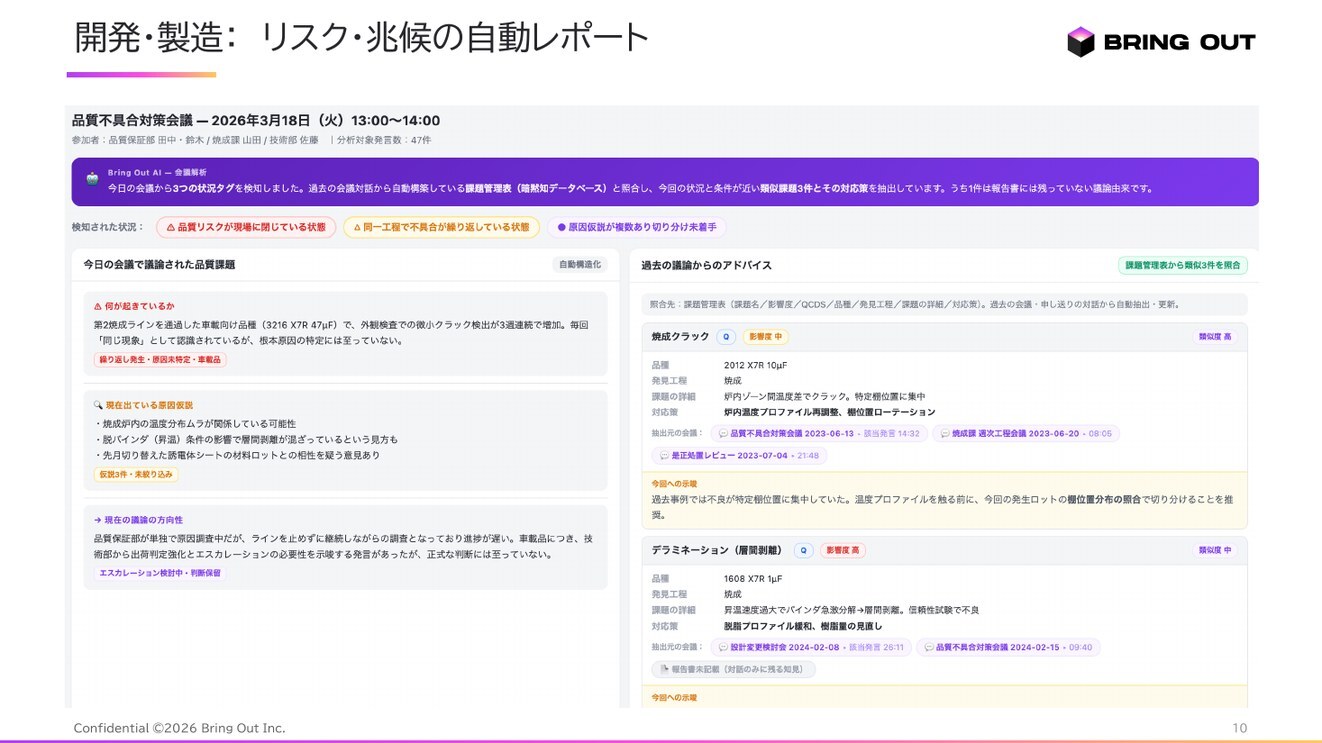
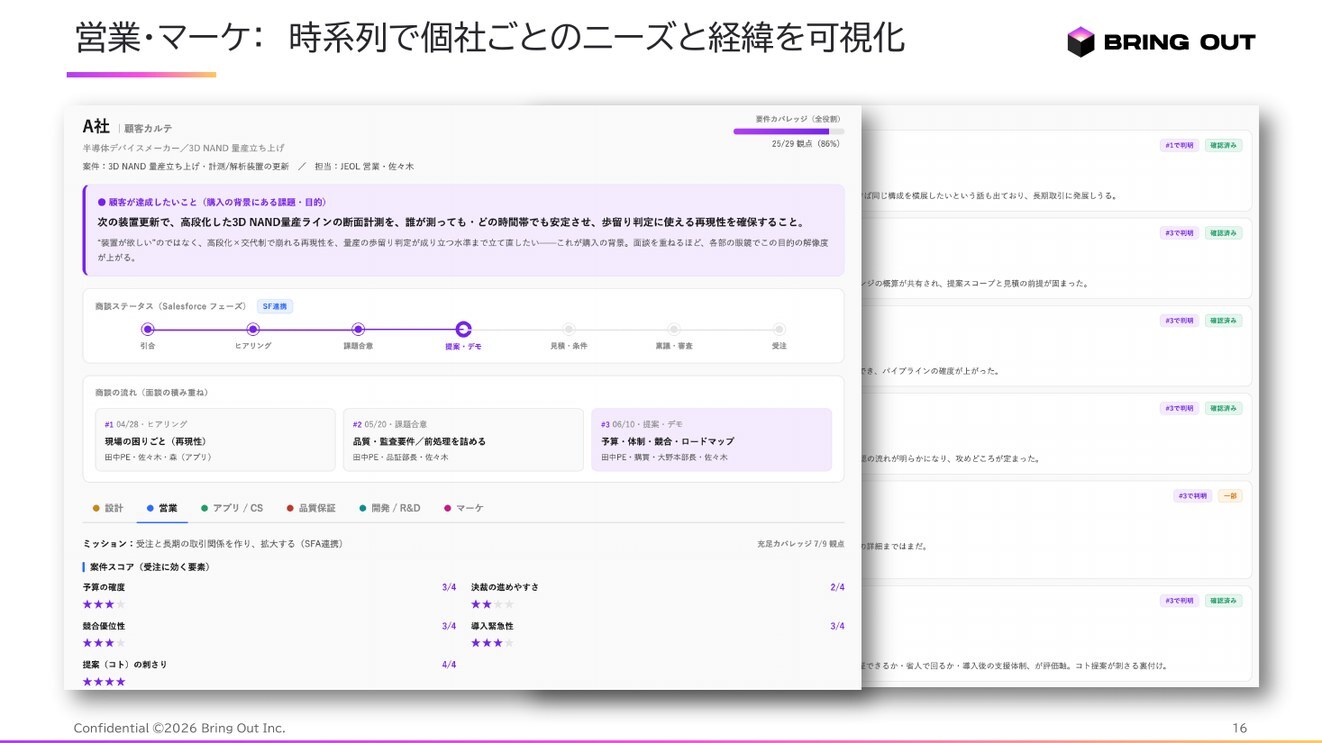
これは、日本企業のAX担当者に私が常に伝えていることでもある。基幹システムを書き換える前に、まず「現場で最も新鮮な一次情報がどこに発生しているか」を見つけ、そこに小さな経路を通すこと。商談、顧客サポート、現場巡回——どこでもよい。重要なのは、まだ要約されていない、加工されていない情報の入口を見つけることだ。
私たちが現場で運用している方法論は、「探索→固定→進化」というサイクルである。蓄積された一次情報に対しアドホックな問いを投げて洞察を発見し(探索)、その問いをKPIに翻訳して縦断的にモニタリングし(固定)、行動変化の結果から次の問いを生成する(進化)。重要なのは、サイクルが回るほどコンテキストが組織の中に資産として積み上がる、という設計だ。MITが言うセマンティック層を持つとは、技術的にデータ基盤を整えるだけでなく、組織として問いを設計し続ける能力を持つことでもある。
AIエージェント時代の競争軸は、データの量でも、モデルの賢さでもない。自社の文脈をどれだけ深く、新鮮に、構造化して持っているか——その一点に収斂していく。経営者が明日から考えるべき問いは、「うちのAIをどう賢くするか」ではない。「うちの一次情報は、いま誰に、どんな鮮度で届いているか」。経営者一人ひとりが、自分のデスクで答えるべき問いである。
Bring Outとは
「対話をデータ化して経営を変革する」ことを掲げ、AIを活用した経営変革(AX:AI Transformation)を行うAXファームです。経営変革の焦点となる論点を定め、その論点をAIプロダクトに埋め込み現場で自走させ、この設計と実装を外部に切り分けず一体で行うことでスピーディに現場へ展開します。コンテクストエンジニアリングによる対話設計、独自のAIエージェント基盤、カスタマイズエージェントが動くソフトウェアの3つを通じて、経営変革を一過性のプロジェクトで終わらせず「常在化」させます。

.png)
-2.png)
-1.png)