


ある大手企業の経営会議で、事業部長が「現場の手応えは悪くない」と報告しました。役員は「では進めよう」と判断しました。半年後、その案件は失注していました。後から商談の録音を聞き直すと、顧客は三度、価格ではなく導入後の運用体制に懸念を示していました。その懸念は、報告書のどこにも書かれていませんでした。
経営判断の質は、現場の対話がどれだけ丸められずに届くかで決まります。ところが日本企業の多くは、最も判断を分ける情報を、報告という要約の工程で失っています。商談、面談、会議。組織のなかで一日に何千時間と交わされる対話は、ほとんどが言葉として消えていきます。残るのは「手応えは悪くない」という、誰の判断材料にもならない一行です。
この、非構造の対話を構造化し、経営判断に使えるデータへ変える営みを、私たちは「コンテキストエンジニアリング」と呼んでいます。これは、私たちが掲げるAX(AI Transformation、AIによる経営変革)を企業のなかに実装するための、中核の方法論です。本稿は、いまAIの世界で語られているコンテキストエンジニアリングという言葉を、経営の方法論として捉え直す試みです。
この記事の3つの結論
- コンテキストエンジニアリングとは、商談という非構造の対話文脈を構造化し、経営判断に使えるデータへ変える営みです。技術用語ではなく経営の方法論です。
- AIの文脈では「文脈窓に適切な情報を満たす技術」を指しますが[1]、企業に必要なのは対話そのものを資産化する設計です。
- 問うべきは「どのAIを入れるか」ではありません。「我が社の対話は、いま誰の判断に届く形になっているか」です。
コンテキストエンジニアリングという言葉は、いま二つの意味を持っています
この言葉は、2025年にAIの実装現場から広がりました。元テスラAI責任者でOpenAI共同創業者のアンドレイ・カルパシー氏は、コンテキストエンジニアリングを「次の一手のために、文脈窓(AIが一度に読み込める作業領域)へちょうど良い情報を満たす、繊細な技術と科学」と定義しています[1]。一つの指示文を磨くプロンプトエンジニアリングが「どう伝えるか」の技術だとすれば、コンテキストエンジニアリングは「何をAIに見せるか」を設計する、より広い工学です[2]。
カルパシー氏は、もう一つ示唆に富む比喩を残しています。大規模言語モデル(LLM)は新しい種類の基本ソフト(OS)のようなもので、モデルが処理装置、文脈窓が作業記憶にあたる、という見立てです[1]。どの情報を作業記憶に載せるかが、AIの成否を分けます。私たちが「経営OS」と呼んできた概念と、この比喩は驚くほど重なります。
ただし、この技術的な定義だけでは、経営の論点は半分しか見えません。AIの文脈窓に何を載せるかを設計する前に、そもそも企業の対話が「載せられる形」になっているか、という問いが残るからです。多くの企業に欠けているのは、AIに渡すデータではなく、対話を資産として残す設計そのものです。ここに、コンテキストエンジニアリングという言葉のもう一つの意味があります。技術の話を、経営の方法論へ引き上げる必要があるのです。
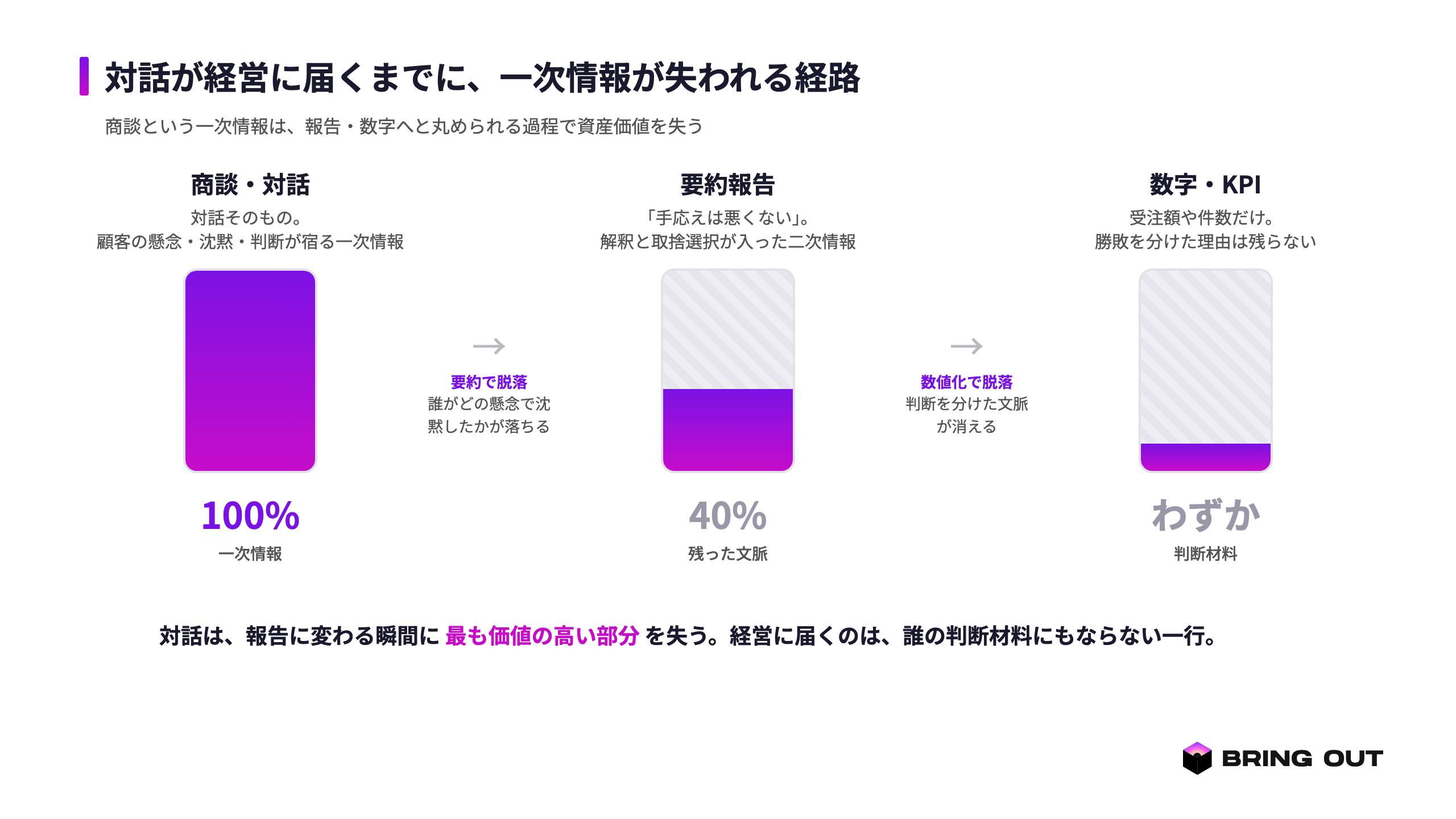
対話は、報告に変わる瞬間に資産価値を失います
経営学で「暗黙知」と「形式知」を対にして論じたのは、野中郁次郎氏・竹内弘高氏の『知識創造企業』です[3]。形式知はマニュアルや数値のように言葉にできる知識、暗黙知は経験や勘として身についていて言葉にしにくい知識を指します。そして、組織の知が育つ循環を描いたのがSECIモデル(暗黙知と形式知が相互に変換され組織の知が育つ枠組み。共同化・表出化・連結化・内面化の4工程からなる)です[3]。
このうち、暗黙知を言葉や形に変える工程を「表出化」と呼びます。実は、4工程のうち表出化だけが、ずっと難所でした。本人すら気づいていない判断基準を引き出す作業は、長らく人手と時間に頼るしかなかったからです。私たちはこの構造的な詰まりを「表出化の壁」と呼んできました。
商談という対話は、表出化されないまま消えていく暗黙知の宝庫です。顧客がどの言葉に反応し、どの懸念で沈黙し、何が意思決定を分けたのか。それらの一次情報は、現場の頭のなかにあります。ところが組織の仕組みは、それを「手応えは悪くない」という報告へ要約してしまいます。私たちはこの状態を「二次情報依存」と呼んできました。要約レポートや加工済みの数字に頼り、勝敗を分けた生の判断が経営に届かない状態のことです。対話は、報告に変わる瞬間に、最も価値の高い部分を失うのです。
コンテキストエンジニアリングとは、対話を構造化してデータに変える設計です
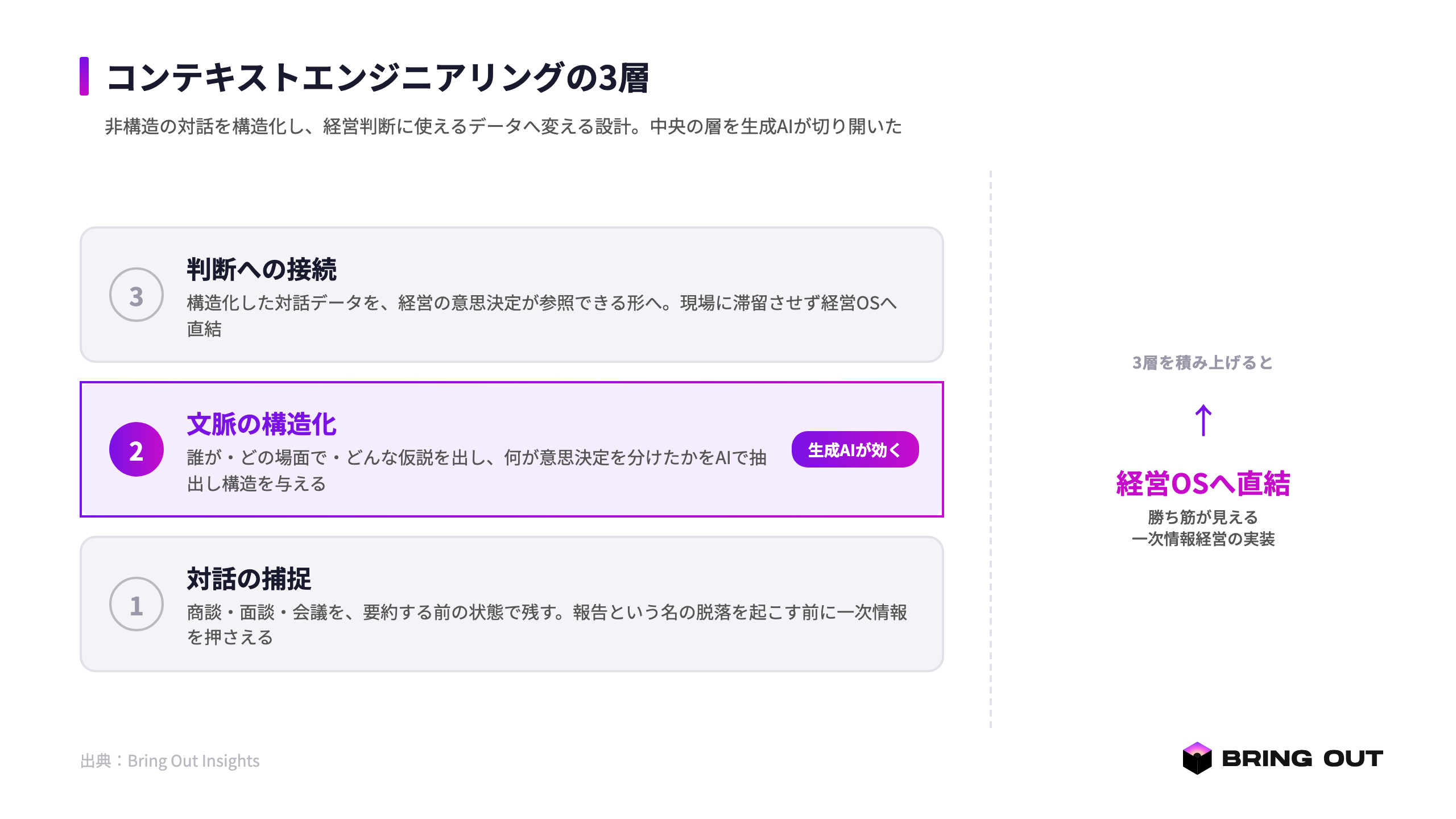
ここで、コンテキストエンジニアリングを経営の方法論として定義し直します。コンテキストエンジニアリングとは、商談や会議という非構造の対話文脈を構造化し、経営判断に使えるデータへ変える設計の営みです。AIの文脈窓を最適化する技術が「AIに何を見せるか」を設計するのと同じ構えで、企業におけるコンテキストエンジニアリングは「経営に何を見せるか」を設計します。対象が文脈窓ではなく経営OSである、という違いです。
この設計は、三つの層からなります。
- 対話の捕捉:商談・面談・会議の音声やテキストを、要約する前の状態で残します。報告という名の脱落を起こす前に、一次情報そのものを押さえる層です。
- 文脈の構造化:誰が、どの場面で、どんな仮説を出し、何が意思決定を分けたのかを、AIで抽出して構造を与えます。私たちが「暗黙知の構造化」と呼んできた工程の中核です。
- 判断への接続:構造化された対話データを、経営の意思決定が参照できる形へ接続します。データが現場に滞留せず、経営OSに直結する層です。
2023年に生成AIが切り開いたのは、この中央の層です。マッキンゼーが公表した調査によれば、生成AIの最大のインパクトは、これまで自動化が最も難しいとされてきた意思決定と協働の領域に及びます。管理・人材育成を自動化できる割合は、2017年の16%から2023年には49%へ跳ね上がりました[4]。重要なのは、生成AIが定型業務を置き換えるという話ではなく、非構造の対話から判断の構造を取り出せるようになった、という点です。表出化の壁が、初めて技術的に崩せるようになったのです。
2026年4月、KADOKAWAから拙著『生成AIで最強の組織が生まれる──トップと現場をつなぐ一次情報経営』を刊行しました。本書の中核命題は、現場の一次情報を要約に変える前に構造化し、経営判断へ直結させるべきだ、というものです。コンテキストエンジニアリングは、この一次情報経営を実装する具体的な方法論にあたります。
対話をデータに変えると、勝ち筋が見えてきます
私たちはこれまで、国内大手企業を中心に1,000名以上、計2万時間に及ぶ商談データのAI解析結果を公表しました[5]。これは、対話をコンテキストエンジニアリングの三層に通した実践そのものです。そこで見えてきたのは、成果を分けているのが「聞く力」ではない、という事実でした。ハイパフォーマーは、業界によってローパフォーマーの2.0倍から3.2倍の頻度で、顧客に「仮説」をぶつけていました[5]。IT業界で2.0倍、人材業界で3.2倍、M&A業界で1.9倍です。「お客様の話をよく聞きなさい」という日本の営業教育を、データが否定したのです。私たちはこれを「傾聴の呪縛」と名づけました。
この勝ち筋は、これまで完全に暗黙知でした。トップ営業の頭のなかにあり、本人も言語化できず、辞めれば消えていきました。それを対話データから構造化し、誰もが使える形へ落とし込む。これがコンテキストエンジニアリングの帰結です。鍵になるのは、個人スキルではなく、組織として仮説を生成し共有する仕組みを持つことです。
これを実践した例が日本M&Aセンター様です。営業の属人的な暗黙知を引き出し、形式知化することを起点に、商談に潜む本質的な情報をデータとして押さえ、会話量や顧客から得られた示唆を数値化していきました。その結果、シナジーに関する仮説提案にかける時間が受注率に最も寄与することを特定し、商談を100点満点で可視化できるようになっています。これは、対話という非構造の文脈を、経営が参照できるデータへ変えたコンテキストエンジニアリングの一例です。
この方法論は、商談に限りません。ある会社では、毎週の経営レビューを、商談の録音解析から組み上げた一枚のダッシュボードを確認して回しています。事業部ごとにOKRの進捗が点数化され、その横に、商談の対話から拾い上げた事実が並びます。たとえば、受注を左右するある提案トークの実施率が、部署によって2割から7割まで開いていること。商談でいま最も引っかかっている論点は何か。次の施策に向けて、現場の要望が何件積み上がっているか。どれも、対話を構造化しなければ決して数字にならなかった一次情報です。
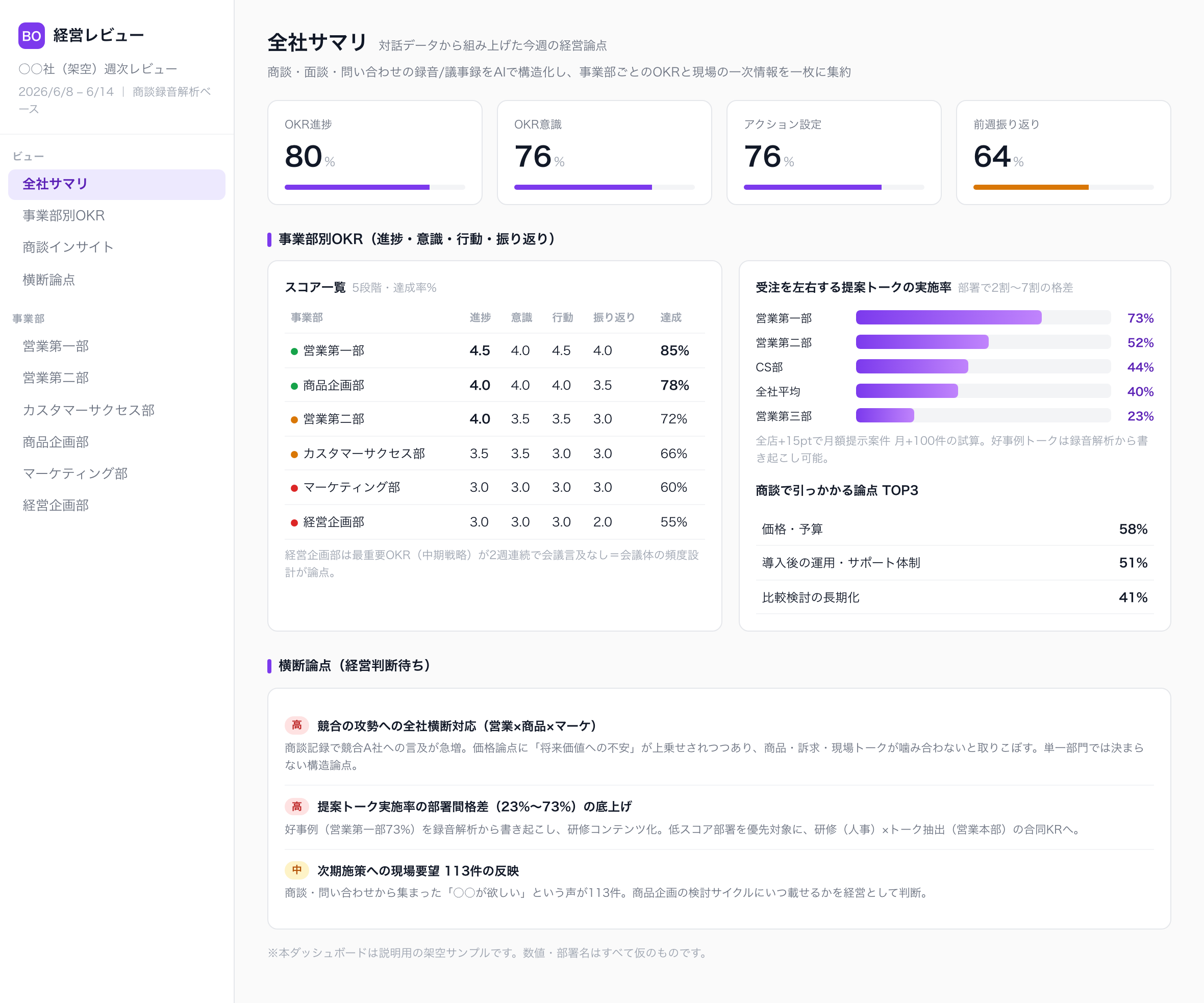
大事なのは、これらが部署ごとにバラバラの報告として上がるのではなく、一枚の画面に横断して並ぶことです。現場が感じている競合の動き、商談に潜む弱点、商品や施策への要望が、つながって見える。本来なら別々の部署に埋もれて、手遅れになるまで気づかれなかった兆候が、先に表面化する。だから経営は、次の一手を勘ではなくデータを根拠に判断できます。対話をデータに変えるとは、こういうことです。
ここで強調したいのは、これがツール導入の話ではない、ということです。ツールにできるのは記録と汎用的なスコアリングまでです。どの対話が判断を分ける一次情報なのかを論点として定め、構造化の設計をするのは、経営の仕事です。私たちがAXファーム(AIによる経営変革を専門に担うファーム)として企業を支援しているのは、まさにこの設計の一点においてです。
カテゴリを輸入するのではなく、自ら定義する側に立つ
コンテキストエンジニアリングという言葉は、いまAIの実装現場で急速に広がっています。多くの企業は、この新しい言葉を「AIに渡すデータを整える技術」として輸入し、ツール選定の議論に落とし込むでしょう。それも一つの理解です。しかし、技術の語彙を経営の方法論へ引き上げない限り、コンテキストエンジニアリングは情報システム部門の話に終わります。
AX(AI Transformation)の競争軸は、どのAIを導入したかでも、データ基盤の容量でもありません。組織のなかで日々消えていく対話文脈を、どれだけ欠落なく構造化し、経営判断へ直結させられるか。コンテキストエンジニアリングとは、その回路を経営OSの中核に据える設計思想にほかなりません。一次情報経営とは、この設計を経営の仕事として引き受けることです。
経営者が明日から考えるべき問いは、「どのAIツールを入れるか」ではありません。「我が社で最も判断を分けている対話は、いま誰の頭のなかにあり、それは経営に届くデータになっているか」。CTO・CDO・経営企画の一人ひとりが、自分のデスクで答えるべき問いだと思います。
出典
- コンテキストエンジニアリングの定義「次の一手のために、文脈窓へちょうど良い情報を満たす、繊細な技術と科学」 — Andrej Karpathy 氏(OpenAI共同創業者・元テスラAI責任者)がX(旧Twitter)で提唱(2025年6月25日)。なお「LLM=新しいOS/モデル=処理装置/文脈窓=作業記憶」の比喩は、同氏の講演「Software 3.0」(2025年)での見立て(定義の投稿とは別の発信)。
- プロンプトエンジニアリングは「どう伝えるか」、コンテキストエンジニアリングは「何を見せるか」でその上位集合 — 各種実装解説(Firecrawl, Nearform, Glean ほか/2025年)。コンテキストエンジニアリングは2025年中頃に台頭。
- 暗黙知/形式知・SECIモデル(共同化・表出化・連結化・内面化) — 野中郁次郎・竹内弘高『知識創造企業』(東洋経済新報社/英語版 The Knowledge-Creating Company, Oxford University Press 1995)。野中氏は1990年前後に知識創造理論を提唱し、1995年に同書でSECIモデルとして体系化。
- 生成AIの最大インパクトは意思決定・協働の知識労働、管理/人材育成の自動化可能割合16%(2017)→49%(2023) — McKinsey「The economic potential of generative AI: The next productivity frontier」(2023年6月)。
- 2万時間・1,000名以上の商談解析、仮説提示 IT2.0/人材3.2/M&A1.9倍、傾聴の呪縛 — Bring Out 自社リサーチ(公開済み数値)。
- 日本M&Aセンター様:営業の属人的暗黙知を形式知化、シナジー仮説提案時間が受注率に最も寄与 — Bring Out 公開事例(非公開数値は不使用)。