~事前にサマリやメタ情報を付与してLLMにかけることで、高精度な横断分析を実現~
株式会社ブリングアウト(以下、ブリングアウト / 本社:東京都中央区 / 代表取締役社長:中野 慧)は、「複数の面談データを効率的・高精度に横断分析する」技術に関する特許(特許第7645021号)を2025年3月5日付で取得いたしました。
本特許は、大規模言語モデル(LLM)を用いた面談分析のコストやコンテキスト長の制約といった課題に着目し、各面談ごとにサマリやメタ情報をあらかじめ付与する独自プロセスを開発。
本特許により、複数の商談・面接などをまとめて高精度に解析することを実現し、単なる録音・書き起こしや振り返りの域を超え、面談内容を多面的に可視化することで企業の売上向上や組織力強化に貢献します。
1. 背景と目的 ~何のための特許か~
リモートワークの普及以前より遠隔での商談や面接のニーズは確かに存在していました。しかし、近年の急速なデジタル化によりオンライン・対面を問わず多様な「面談機会」がさらに増加しているのが現状です。
大規模言語モデル(LLM)などのAI技術が進化したことで、これまで人手では困難だった面談内容を書き起こした上でデータ化し、質的向上につなげる取り組みは徐々にに普及してきましたが、既存の多くのツールは、単一商談または1回の面接の書き起こし結果を扱うにとどまり、「重要ポイントの抜け漏れ」や「学習効果の横展開」が必ずしも十分ではないという課題がありました。
さらに複数の対話データを単純に全データを大規模言語モデルへ一括投入すると、以下のような問題が生じがちでした。
コンテキスト長の制約(モデルが一度に扱えるテキスト量には上限が存在)
推論コストの高騰(長文を処理するとAPI利用料・サーバー負荷が急増)
分析精度の低下(長いテキストを無造作に与えると要点が埋もれやすい)
本特許は、こうした課題を解消しつつ、複数の面談を横断的に分析できる仕組みを提供するものです。
2. 特許の強み ~どんなメリットがあるか~
(1)大容量データの扱いやすさ
面談ごとに事前に要約(サマリ)やスコアリング、メタ情報を付与してからLLMに渡すため、コンテキストの長さを最適化しつつ、複数面談を横断した高精度な分析が可能です。
(2)複数面談を横断的に評価
面談を1件ずつ振り返るだけでなく、累積データをまとめて解析して「似たような懸念点」「成功パターン」などを抽出しやすくなります。
(3)コスト削減・分析工数の短縮
無駄なテキストをLLMに大量投入しない分、API利用料や処理時間を削減できるほか、担当者の手動チェック工数も大幅に減らせます。
(4)BOIなどの機能との相性
事前に付与したメタ情報を使った解析やリコメンド機能(BOI: Bring Out Insightなど)がシームレスに連携し、さらなる付加価値を生み出します。
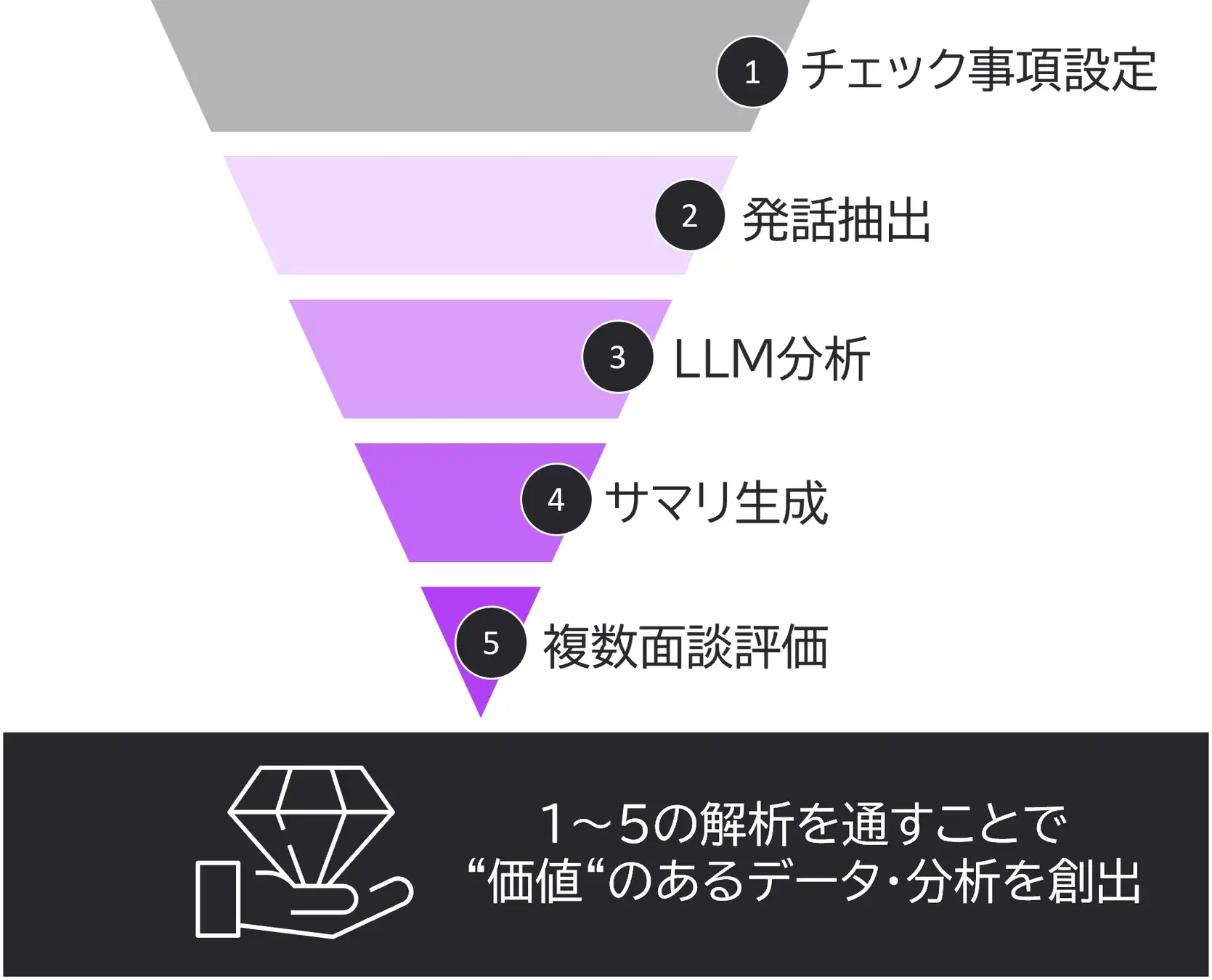
3. 特許の概要
今回取得した特許の中心的なポイントは、以下のプロセスを一体化して行うことにあります。
チェック事項保持
あらかじめ「面談のポイント」(例:課題、予算、導入意向)などの項目を複数設定し、「何を確認すべきか」を明確に管理。
面談の発話データから関連部分を抽出
音声や映像を文字起こしし、その中から各チェック事項と結びつくテキスト(関連発話テキスト)を抽出する。
大規模言語モデルを使った“該否値”の取得
面談内容をLLMに入力して「チェック事項ごとに達成しているか?」「どの程度か?」を数値・指標(該否値)として算出。
同じくLLMを使ったサマリ生成
抽出した関連発話テキストをもとに、チェック事項ごとのやり取りを自動要約して要点を可視化。
複数面談をまとめて評価し、回答を導く
さらに複数回の商談や面接を「まとめて分析」する指示をLLMに与え、(3)の該否値と(4)のサマリを踏まえて、「共通する課題は?」「どの面談が成功度高い?」などの回答を生成させる。
このプロセスにより、大量の面談データを一度に処理する際にも、コンテキストを最適化しながら高精度な分析を実現します。
4. 今後の展開
当社は、本特許技術を活用した「面談評価システム」の普及を通じ、商談・面接・社内会議などあらゆる面談シーンの質向上を目指します。
今後はさらに多角的な解析機能を追加し、企業の事業活動全般におけるコミュニケーション精度向上に貢献してまいります。

今回の特許取得は、当社の面談評価技術のコアを守るだけでなく、ビジネスコミュニケーション全体を変革する大きな一歩だと考えています。私たちは大規模言語モデルを駆使し、複数の対話データを横断的に解析して“共通の論点”を抽出する独自アルゴリズムを構築してきました。これは単なる文字起こしにとどまらず、“チェック事項”を起点にサマリを導き出し、該否値で評価するという新しい仕組みです。
日々進化していくテクノロジーを導入することを継続していくことによって、より深いインサイトを得られる技術開発を進めます。たとえば、自分が参加していない会議・商談においても潜在的な課題や機会を早期に見つけ出せるようになるでしょう。私たちは、面談の質を高めるためのテクノロジーを日々進化させ、企業や組織の意思決定を根本からアップデートしたいと考えています。
未来を見据えると、地理的・言語的な壁を超え、コミュニケーションはシームレスかつサポートされる世界がやって来ます。当社のシステムが”対話データの集積と解析”を高度化し、さまざまな意思決定のスピードと質を上げることで、企業の成長のみならず社会全体のイノベーションにも寄与できると確信しています。引き続き、挑戦を続けてまいります。
【関連リンク】
【CEO Comment】
今回の特許取得は、私たちが一貫して取り組んできた「一次情報を、組織が扱える形に変える」ためのコア技術を形にしたものです。
面談データは価値が高い一方、量が増えるほどLLMのコンテキストやコストの壁にぶつかり、ただ全部を投入するだけでは精度も落ちてしまいます。そこで各面談にサマリやスコア、メタ情報を事前に付与し、チェック事項を軸に該否値と要点を整理してから横断分析することで、現実的なコストで高精度な“全体像”を引き出せるようにしました。これは議事録を超えて、成功パターンや共通論点を組織で再利用できる状態をつくる、まさにコンテクストエンジニアリングの実装です。
今後はBOIなどの機能とも連携し、対話データを経営資産へ変換するスピードと深さをさらに高めていきます。

【株式会社ブリングアウト】
株式会社ブリングアウトは、「対話をデータ化して経営を変革する」ことを掲げています。
①企業や利用シーンに合わせた対話情報の活用設計や対話内容を構造設計(コンテクストエンジニアリング)を行うコンサルタントチームと、 ②言語解析を行う独自開発のAIインフラ、 ③分析結果に基づいて企業に合わせた要約や解析結果を表出させる特許取得済みのソフトウェアの3点で構成されたサービスを提供しています。
東洋経済のすごいベンチャー100や日経の未来の市場を創る100社など数々の受賞歴を持ち、数多くの大企業でサービス利用されています。
【会社概要】
会社名:株式会社ブリングアウト 代表者:代表取締役社長 中野 慧 所在地:東京都中央区銀座1丁目22番11号 銀座大竹ビジデンス2階 設立:2020年12月 事業内容:DX支援コンサルティング、AIを活用した生産性向上SaaSの開発・提供 URL:https://www.bringout.biz